ml_algo module¶
This module contains the base class for machine learning algorithms.
Machine learning is the art of building models from data, the latter being samples of properties of interest that can sometimes be sorted by group, such as inputs, outputs, categories, …
In the absence of such groups, the data can be analyzed through a study of commonalities, leading to plausible clusters. This is referred to as clustering, a branch of unsupervised learning dedicated to the detection of patterns in unlabeled data.
See also
When data can be separated into at least two categories by a human, supervised learning can start with classification whose purpose is to model the relations between these categories and the properties of interest. Once trained, a classification model can predict the category corresponding to new property values.
See also
When the distinction between inputs and outputs can be made among the data properties, another branch of supervised learning can be considered: regression modeling. Once trained, a regression model can predict the outputs corresponding to new inputs values.
See also
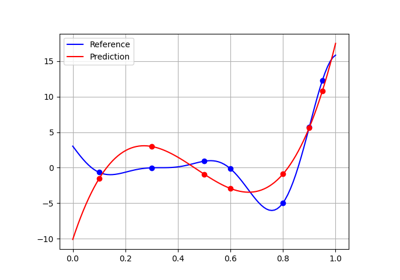
The quality of a machine learning algorithm can be measured
using an MLQualityMeasure
either with respect to the learning dataset
or to a test dataset or using resampling methods,
such as K-folds or leave-one-out cross-validation techniques.
The challenge is to avoid over-learning the learning data
leading to a loss of generality.
We often want to build models that are not too dataset-dependent.
For that,
we want to maximize both a learning quality and a generalization quality.
In unsupervised learning,
a quality measure can represent the robustness of clusters definition
while in supervised learning, a quality measure can be interpreted as an error,
whether it is a misclassification in the case of the classification algorithms
or a prediction one in the case of the regression algorithms.
This quality can often be improved
by building machine learning models from standardized data
in such a way that the data properties have the same order of magnitude.
See also
Lastly, a machine learning algorithm often depends on hyperparameters to be carefully tuned in order to maximize the generalization power of the model.
See also
- class gemseo.mlearning.core.ml_algo.MLAlgo(data, transformer=mappingproxy({}), **parameters)[source]¶
Bases:
objectAn abstract machine learning algorithm.
Such a model is built from a training dataset, data transformation options and parameters. This abstract class defines the
MLAlgo.learn(),MLAlgo.save()methods and the boolean property,MLAlgo.is_trained. It also offers a string representation for end users. Derived classes shall overload theMLAlgo.learn(),MLAlgo._save_algo()andMLAlgo._load_algo()methods.- Parameters:
data (Dataset) – The learning dataset.
transformer (TransformerType) –
The strategies to transform the variables. The values are instances of
Transformerwhile the keys are the names of either the variables or the groups of variables, e.g."inputs"or"outputs"in the case of the regression algorithms. If a group is specified, theTransformerwill be applied to all the variables of this group. IfIDENTITY, do not transform the variables.By default it is set to {}.
**parameters (MLAlgoParameterType) – The parameters of the machine learning algorithm.
- Raises:
ValueError – When both the variable and the group it belongs to have a transformer.
- learn(samples=None, fit_transformers=True)[source]¶
Train the machine learning algorithm from the learning dataset.
- load_algo(directory)[source]¶
Load a machine learning algorithm from a directory.
- Parameters:
directory (str | Path) – The path to the directory where the machine learning algorithm is saved.
- Return type:
None
- to_pickle(directory=None, path='.', save_learning_set=False)[source]¶
Save the machine learning algorithm.
- Parameters:
directory (str | None) – The name of the directory to save the algorithm.
path (str | Path) –
The path to parent directory where to create the directory.
By default it is set to “.”.
save_learning_set (bool) –
Whether to save the learning set or get rid of it to lighten the saved files.
By default it is set to False.
- Returns:
The path to the directory where the algorithm is saved.
- Return type:
- DEFAULT_TRANSFORMER: DefaultTransformerType = mappingproxy({})¶
The default transformer for the input and output data, if any.
- DataFormatters: ClassVar[type[BaseDataFormatters]]¶
The data formatters for the learning and prediction methods.
- IDENTITY: Final[DefaultTransformerType] = mappingproxy({})¶
A transformer leaving the input and output variables as they are.
- SHORT_ALGO_NAME: ClassVar[str] = 'MLAlgo'¶
The short name of the machine learning algorithm, often an acronym.
Typically used for composite names, e.g.
f"{algo.SHORT_ALGO_NAME}_{dataset.name}"orf"{algo.SHORT_ALGO_NAME}_{discipline.name}".
- algo: Any¶
The interfaced machine learning algorithm.
- property learning_samples_indices: Sequence[int]¶
The indices of the learning samples used for the training.
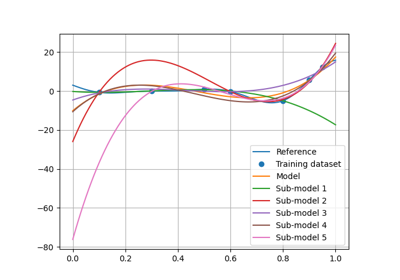
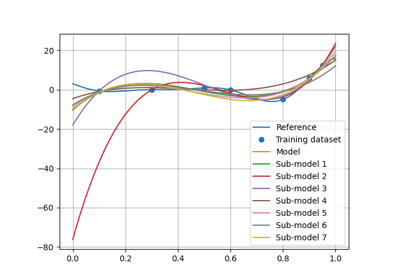
- resampling_results: dict[str, tuple[Resampler, list[MLAlgo], list[ndarray] | ndarray]]¶
The resampler class names bound to the resampling results.
A resampling result is formatted as
(resampler, ml_algos, predictions)whereresampleris aResampler,ml_algosis the list of the associated machine learning algorithms built during the resampling stage andpredictionsare the predictions obtained with the latter.resampling_resultsstores only one resampling result per resampler type (e.g.,"CrossValidation","LeaveOneOut"and"Boostrap").
- transformer: dict[str, Transformer]¶
The strategies to transform the variables, if any.
The values are instances of
Transformerwhile the keys are the names of either the variables or the groups of variables, e.g. “inputs” or “outputs” in the case of the regression algorithms. If a group is specified, theTransformerwill be applied to all the variables of this group.