Note
Click here to download the full example code
Store observables¶
Introduction¶
In this example,
we will learn how to store the history of state variables using the
add_observable() method.
This is useful in situations where we wish to access, post-process,
or save the values of discipline outputs that are not design variables,
constraints or objective functions.
The Sellar problem¶
We will consider in this example the Sellar problem:
where the coupling variables are
and
and where the general constraints are
Imports¶
All the imports needed for the tutorials are performed here. Note that some of the imports are related to the Python 2/3 compatibility.
from __future__ import division, unicode_literals
from matplotlib import pyplot as plt
from numpy import array, ones
from gemseo.algos.design_space import DesignSpace
from gemseo.api import configure_logger, create_discipline, create_scenario
configure_logger()
Out:
<RootLogger root (INFO)>
Create the problem disciplines¶
In this section,
we use the available classes Sellar1, Sellar2
and SellarSystem to define the disciplines of the problem.
The create_discipline() API function allows us to
carry out this task easily, as well as store the instances in a list
to be used later on.
disciplines = create_discipline(["Sellar1", "Sellar2", "SellarSystem"])
Create and execute the scenario¶
Create the design space¶
In this section, we define the design space which will be used for the creation of the MDOScenario.
design_space = DesignSpace()
design_space.add_variable("x_local", 1, l_b=0.0, u_b=10.0, value=ones(1))
design_space.add_variable(
"x_shared", 2, l_b=(-10, 0.0), u_b=(10.0, 10.0), value=array([4.0, 3.0])
)
Create the scenario¶
In this section, we build the MDO scenario which links the disciplines with the formulation, the design space and the objective function.
scenario = create_scenario(
disciplines, formulation="MDF", objective_name="obj", design_space=design_space
)
Add the constraints¶
Then, we have to set the design constraints
scenario.add_constraint("c_1", "ineq")
scenario.add_constraint("c_2", "ineq")
Add the observables¶
Only the design variables, objective function and constraints are stored by
default. In order to be able to recover the data from the state variables,
y1 and y2, we have to add them as observables. All we have to do is enter
the variable name as a string to the
add_observable() method.
If more than one output name is provided (as a list of strings),
the observable function returns a concatenated array of the output values.
scenario.add_observable("y_1")
It is also possible to add the observable with a custom name, using the option observable_name. Let us store the variable y_2 as y2.
scenario.add_observable("y_2", observable_name="y2")
Execute the scenario¶
Then, we execute the MDO scenario with the inputs of the MDO scenario as a dictionary. In this example, the gradient-based SLSQP optimizer is selected, with 10 iterations at maximum:
scenario.execute(input_data={"max_iter": 10, "algo": "SLSQP"})
Out:
INFO - 21:50:03:
INFO - 21:50:03: *** Start MDO Scenario execution ***
INFO - 21:50:03: MDOScenario
INFO - 21:50:03: Disciplines: Sellar1 Sellar2 SellarSystem
INFO - 21:50:03: MDOFormulation: MDF
INFO - 21:50:03: Algorithm: SLSQP
INFO - 21:50:03: Optimization problem:
INFO - 21:50:03: Minimize: obj(x_local, x_shared)
INFO - 21:50:03: With respect to: x_local, x_shared
INFO - 21:50:03: Subject to constraints:
INFO - 21:50:03: c_1(x_local, x_shared) <= 0.0
INFO - 21:50:03: c_2(x_local, x_shared) <= 0.0
INFO - 21:50:03: Design space:
INFO - 21:50:03: +----------+-------------+-------+-------------+-------+
INFO - 21:50:03: | name | lower_bound | value | upper_bound | type |
INFO - 21:50:03: +----------+-------------+-------+-------------+-------+
INFO - 21:50:03: | x_local | 0 | 1 | 10 | float |
INFO - 21:50:03: | x_shared | -10 | 4 | 10 | float |
INFO - 21:50:03: | x_shared | 0 | 3 | 10 | float |
INFO - 21:50:03: +----------+-------------+-------+-------------+-------+
INFO - 21:50:03: Optimization: 0%| | 0/10 [00:00<?, ?it]
/home/docs/checkouts/readthedocs.org/user_builds/gemseo/conda/3.2.0/lib/python3.8/site-packages/scipy/sparse/linalg/dsolve/linsolve.py:407: SparseEfficiencyWarning: splu requires CSC matrix format
warn('splu requires CSC matrix format', SparseEfficiencyWarning)
INFO - 21:50:03: Optimization: 50%|█████ | 5/10 [00:00<00:00, 80.99 it/sec, obj=3.18]
INFO - 21:50:03: Optimization: 80%|████████ | 8/10 [00:00<00:00, 54.19 it/sec, obj=3.18]
INFO - 21:50:03: Optimization result:
INFO - 21:50:03: Objective value = 3.1833939505271727
INFO - 21:50:03: The result is feasible.
INFO - 21:50:03: Status: None
INFO - 21:50:03: Optimizer message: Successive iterates of the objective function are closer than ftol_rel or ftol_abs. GEMSEO Stopped the driver
INFO - 21:50:03: Number of calls to the objective function by the optimizer: 9
INFO - 21:50:03: Constraints values:
INFO - 21:50:03: c_1 = 1.1283325385136322e-09
INFO - 21:50:03: c_2 = -20.244722233710302
INFO - 21:50:03: Design space:
INFO - 21:50:03: +----------+-------------+-------------------+-------------+-------+
INFO - 21:50:03: | name | lower_bound | value | upper_bound | type |
INFO - 21:50:03: +----------+-------------+-------------------+-------------+-------+
INFO - 21:50:03: | x_local | 0 | 0 | 10 | float |
INFO - 21:50:03: | x_shared | -10 | 1.977638883143948 | 10 | float |
INFO - 21:50:03: | x_shared | 0 | 0 | 10 | float |
INFO - 21:50:03: +----------+-------------+-------------------+-------------+-------+
INFO - 21:50:03: *** MDO Scenario run terminated in 0:00:00.191938 ***
{'max_iter': 10, 'algo': 'SLSQP'}
Access the observable variables¶
Retrieve observables from a dataset¶
In order to create a dataset, we use the
corresponding OptimizationProblem:
opt_problem = scenario.formulation.opt_problem
We can easily build a dataset from this OptimizationProblem:
either by separating the design parameters from the functions
(default option):
dataset = opt_problem.export_to_dataset("sellar_problem")
print(dataset)
Out:
sellar_problem
Number of samples: 8
Number of variables: 7
Variables names and sizes by group:
design_parameters: x_local (1), x_shared (2)
functions: y2 (1), y_1 (1), obj (1), c_1 (1), c_2 (1)
Number of dimensions (total = 8) by group:
design_parameters: 3
functions: 5
or by considering all features as default parameters:
dataset = opt_problem.export_to_dataset("sellar_problem", categorize=False)
print(dataset)
Out:
sellar_problem
Number of samples: 8
Number of variables: 7
Variables names and sizes by group:
parameters: x_local (1), x_shared (2), y2 (1), y_1 (1), obj (1), c_1 (1), c_2 (1)
Number of dimensions (total = 8) by group:
parameters: 8
or by using an input-output naming rather than an optimization naming:
dataset = opt_problem.export_to_dataset("sellar_problem", opt_naming=False)
print(dataset)
Out:
sellar_problem
Number of samples: 8
Number of variables: 7
Variables names and sizes by group:
inputs: x_local (1), x_shared (2)
outputs: y2 (1), y_1 (1), obj (1), c_1 (1), c_2 (1)
Number of dimensions (total = 8) by group:
inputs: 3
outputs: 5
Access observables by name¶
We can get the observable data by name, either as a dictionary indexed by the observable names (default option):
print(dataset.get_data_by_names(["y_1", "y2"]))
Out:
{'y_1': array([[4.21393092],
[2.32004905],
[1.8412013 ],
[1.77871073],
[1.77763921],
[1.77763888],
[1.77763888],
[1.77763888]]), 'y2': array([[11.21393092],
[ 4.84009809],
[ 3.8816114 ],
[ 3.75742147],
[ 3.75527841],
[ 3.75527777],
[ 3.75527777],
[ 3.75527777]])}
or as an array:
print(dataset.get_data_by_names(["y_1", "y2"], False))
Out:
[[ 4.21393092 11.21393092]
[ 2.32004905 4.84009809]
[ 1.8412013 3.8816114 ]
[ 1.77871073 3.75742147]
[ 1.77763921 3.75527841]
[ 1.77763888 3.75527777]
[ 1.77763888 3.75527777]
[ 1.77763888 3.75527777]]
Use the observables in a post-processing method¶
Finally, we can generate plots with the observable variables. Have a look at the Basic History plot and the Scatter Plot Matrix:
scenario.post_process(
"BasicHistory", data_list=["obj", "y_1", "y2"], save=False, show=False
)
scenario.post_process(
"ScatterPlotMatrix",
save=False,
show=False,
variables_list=["obj", "c_1", "c_2", "y2", "y_1"],
)
# Workaround for HTML rendering, instead of ``show=True``
plt.show()
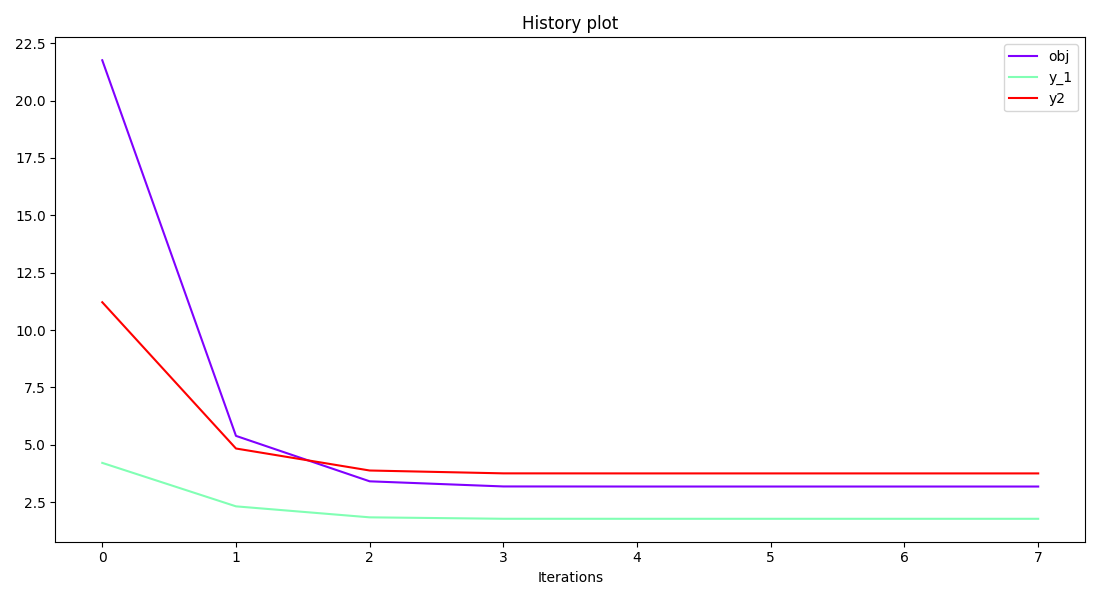
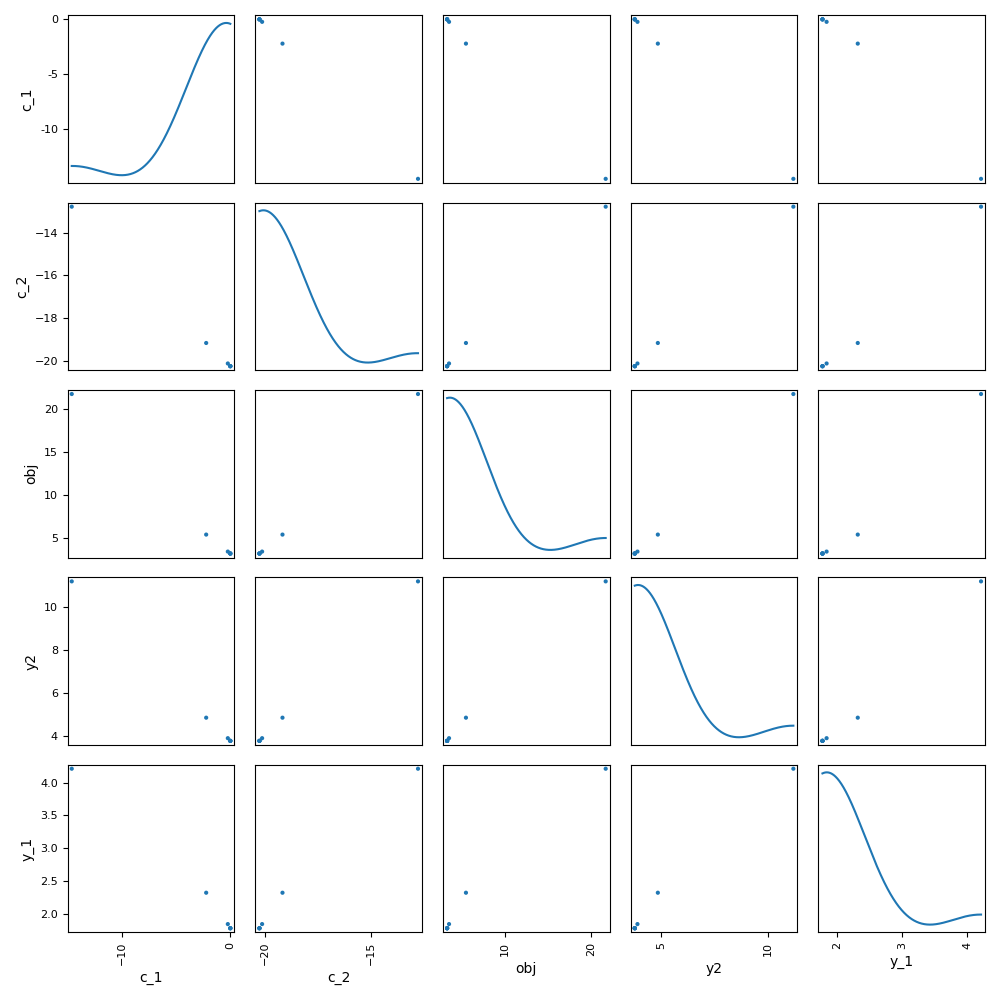
Out:
/home/docs/checkouts/readthedocs.org/user_builds/gemseo/conda/3.2.0/lib/python3.8/site-packages/gemseo/algos/database.py:1373: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
f_history = array(flat_vals).real
Total running time of the script: ( 0 minutes 1.500 seconds)