iris module¶
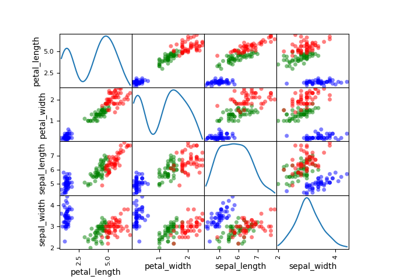
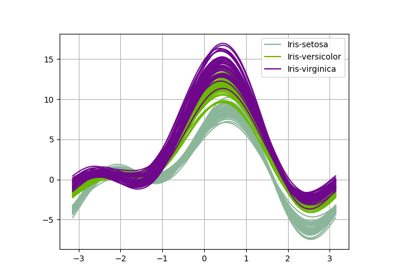
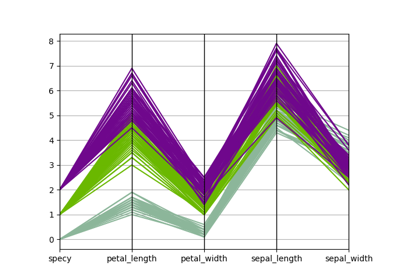
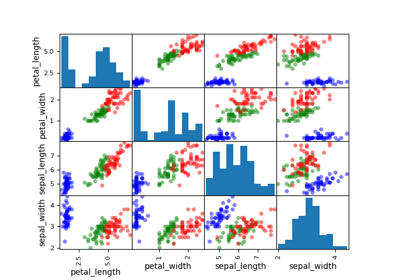
Iris dataset¶
This is one of the best known Dataset
to be found in the machine learning literature.
It was introduced by the statistician Ronald Fisher in his 1936 paper “The use of multiple measurements in taxonomic problems”, Annals of Eugenics. 7 (2): 179–188.
It contains 150 instances of iris plants:
50 Iris Setosa,
50 Iris Versicolour,
50 Iris Virginica.
Each instance is characterized by:
its sepal length in cm,
its sepal width in cm,
its petal length in cm,
its petal width in cm.
This Dataset can be used for either clustering purposes
or classification ones.
- class gemseo.problems.dataset.iris.IrisDataset(name='Iris', by_group=True, as_io=False)[source]¶
Bases:
DatasetIris dataset parametrization.
Constructor.
- Parameters:
name (str) –
By default it is set to “Iris”.
- add_group(group, data, variables=None, sizes=None, pattern=None, cache_as_input=True)¶
Add data related to a group.
- Parameters:
group (str) – The name of the group of data to be added.
data (ndarray) – The data to be added.
variables (list[str] | None) – The names of the variables. If None, use default names based on a pattern.
sizes (dict[str, int] | None) – The sizes of the variables. If None, assume that all the variables have a size equal to 1.
pattern (str | None) – The name of the variable to be used as a pattern when variables is None. If None, use the
Dataset.DEFAULT_NAMESfor this group if it exists. Otherwise, use the group name.cache_as_input (bool) –
If True, cache these data as inputs when the cache is exported to a cache.
By default it is set to True.
- Return type:
None
- add_variable(name, data, group='parameters', cache_as_input=True)¶
Add data related to a variable.
- Parameters:
name (str) – The name of the variable to be stored.
data (ndarray) – The data to be stored.
group (str) –
The name of the group related to this variable.
By default it is set to “parameters”.
cache_as_input (bool) –
If True, cache these data as inputs when the cache is exported to a cache.
By default it is set to True.
- Return type:
None
- compare(value_1, logical_operator, value_2, component_1=0, component_2=0)¶
Compare either a variable and a value or a variable and another variable.
- Parameters:
value_1 (str | float) – The first value, either a variable name or a numeric value.
logical_operator (str) – The logical operator, either “==”, “<”, “<=”, “>” or “>=”.
value_2 (str | float) – The second value, either a variable name or a numeric value.
component_1 (int) –
If value_1 is a variable name, component_1 corresponds to its component used in the comparison.
By default it is set to 0.
component_2 (int) –
If value_2 is a variable name, component_2 corresponds to its component used in the comparison.
By default it is set to 0.
- Returns:
Whether the comparison is valid for the different entries.
- Return type:
ndarray
- export_to_cache(inputs=None, outputs=None, cache_type='MemoryFullCache', cache_hdf_file=None, cache_hdf_node_name=None, **options)¶
Export the dataset to a cache.
- Parameters:
inputs (Iterable[str] | None) – The names of the inputs to cache. If None, use all inputs.
outputs (Iterable[str] | None) – The names of the outputs to cache. If None, use all outputs.
cache_type (str) –
The type of cache to use.
By default it is set to “MemoryFullCache”.
cache_hdf_file (str | None) – The name of the HDF file to store the data. Required if the type of the cache is ‘HDF5Cache’.
cache_hdf_node_name (str | None) – The name of the HDF node to store the discipline. If None, use the name of the dataset.
- Returns:
A cache containing the dataset.
- Return type:
- export_to_dataframe(copy=True, variable_names=None, sort_names=True)¶
Export the dataset, or a part of it, to a pandas DataFrame.
- Parameters:
copy (bool) –
If
True, copy data. Otherwise, use reference.By default it is set to True.
variable_names (Sequence[str] | None) – The variable names to export. If
None, export all the variables.sort_names (bool) –
If
True, sort the columns by group and name. IfFalse, sort only by group.By default it is set to True.
- Returns:
A pandas DataFrame containing the dataset, or a part of it.
- Return type:
DataFrame
- static find(comparison)¶
Find the entries for which a comparison is satisfied.
This search uses a boolean 1D array whose length is equal to the length of the dataset.
- get_all_data(by_group=True, as_dict=False)¶
Get all the data stored in the dataset.
The data can be returned either as a dictionary indexed by the names of the variables, or as an array concatenating them, accompanied by the names and sizes of the variables.
The data can also be classified by groups of variables.
- Parameters:
by_group –
If True, sort the data by group.
By default it is set to True.
as_dict –
If True, return the data as a dictionary.
By default it is set to False.
- Returns:
All the data stored in the dataset.
- Return type:
Union[Dict[str, Union[Dict[str, ndarray], ndarray]], Tuple[Union[ndarray, Dict[str, ndarray]], List[str], Dict[str, int]]]
- get_column_names(variables=None, as_tuple=False, start=0)¶
Return the names of the columns of the dataset.
If dim(x)=1, its column name is ‘x’ while if dim(y)=2, its column names are either ‘x_0’ and ‘x_1’ or ColumnName(group_name, ‘x’, ‘0’) and ColumnName(group_name, ‘x’, ‘1’).
- Parameters:
variables (Sequence[str]) – The names of the variables. If
None, use all the variables.as_tuple (bool) –
If True, return the names as named tuples. otherwise, return the names as strings.
By default it is set to False.
start (int) –
The first index for the components of a variable. E.g. with ‘0’: ‘x_0’, ‘x_1’, …
By default it is set to 0.
- Returns:
The names of the columns of the dataset.
- Return type:
list[str | ColumnName]
- get_data_by_group(group, as_dict=False)¶
Get the data for a specific group name.
- get_data_by_names(names, as_dict=True)¶
Get the data for specific names of variables.
- get_group(variable_name)¶
Get the name of the group that contains a variable.
- get_names(group_name)¶
Get the names of the variables of a group.
- get_normalized_dataset(excluded_variables=None, excluded_groups=None, use_min_max=True, center=False, scale=False)¶
Get a normalized copy of the dataset.
- Parameters:
excluded_variables (Sequence[str] | None) – The names of the variables not to be normalized. If
None, normalize all the variables.excluded_groups (Sequence[str] | None) – The names of the groups not to be normalized. If
None, normalize all the groups.use_min_max (bool) –
Whether to use the geometric normalization \((x-\min(x))/(\max(x)-\min(x))\).
By default it is set to True.
center (bool) –
Whether to center the variables so that they have a zero mean.
By default it is set to False.
scale (bool) –
Whether to scale the variables so that they have a unit variance.
By default it is set to False.
- Returns:
A normalized dataset.
- Return type:
- is_group(name)¶
Check if a name is a group name.
- is_nan()¶
Check if an entry contains NaN.
- Returns:
Whether any entries are NaN or not.
- Return type:
- is_variable(name)¶
Check if a name is a variable name.
- n_variables_by_group(group)¶
The number of variables for a group.
- plot(name, show=True, save=False, file_path=None, directory_path=None, file_name=None, file_format=None, properties=None, **options)¶
Plot the dataset from a
DatasetPlot.See
Dataset.get_available_plots()- Parameters:
name (str) – The name of the post-processing, which is the name of a class inheriting from
DatasetPlot.show (bool) –
If True, display the figure.
By default it is set to True.
save (bool) –
If True, save the figure.
By default it is set to False.
file_path (str | Path | None) – The path of the file to save the figures. If None, create a file path from
directory_path,file_nameandfile_format.directory_path (str | Path | None) – The path of the directory to save the figures. If None, use the current working directory.
file_name (str | None) – The name of the file to save the figures. If None, use a default one generated by the post-processing.
file_format (str | None) – A file format, e.g. ‘png’, ‘pdf’, ‘svg’, … If None, use a default file extension.
properties (Mapping[str, DatasetPlotPropertyType] | None) – The general properties of a
DatasetPlot.**options – The options for the post-processing.
- Return type:
- remove(entries)¶
Remove entries.
- rename_variable(name, new_name)¶
Rename a variable.
- set_from_array(data, variables=None, sizes=None, groups=None, default_name=None)¶
Set the dataset from an array.
- Parameters:
data (ndarray) – The data to be stored.
variables (list[str] | None) – The names of the variables. If None, use one default name per column of the array based on the pattern ‘default_name’.
sizes (dict[str, int] | None) – The sizes of the variables. If None, assume that all the variables have a size equal to 1.
groups (dict[str, str] | None) – The groups of the variables. If None, use
Dataset.DEFAULT_GROUPfor all the variables.default_name (str | None) – The name of the variable to be used as a pattern when variables is None. If None, use the
Dataset.DEFAULT_NAMESfor this group if it exists. Otherwise, use the group name.
- Return type:
None
- set_from_file(filename, variables=None, sizes=None, groups=None, delimiter=',', header=True)¶
Set the dataset from a file.
- Parameters:
filename (Path | str) – The name of the file containing the data.
variables (list[str] | None) – The names of the variables. If None and header is True, read the names from the first line of the file. If None and header is False, use default names based on the patterns the
Dataset.DEFAULT_NAMESassociated with the different groups.sizes (dict[str, int] | None) – The sizes of the variables. If None, assume that all the variables have a size equal to 1.
groups (dict[str, str] | None) – The groups of the variables. If None, use
Dataset.DEFAULT_GROUPfor all the variables.delimiter (str) –
The field delimiter.
By default it is set to “,”.
header (bool) –
If True, read the names of the variables on the first line of the file.
By default it is set to True.
- Return type:
None
- set_metadata(name, value)¶
Set a metadata attribute.
- transform_variable(name, transformation)¶
Transform a variable.
- DEFAULT_NAMES: ClassVar[dict[str, str]] = {'design_parameters': 'dp', 'functions': 'func', 'inputs': 'in', 'outputs': 'out', 'parameters': 'x'}¶
The default variable names for the different groups.
- DESIGN_GROUP: ClassVar[str] = 'design_parameters'¶
The group name for the design variables of an
OptimizationProblem.
- FUNCTION_GROUP: ClassVar[str] = 'functions'¶
The group name for the functions of an
OptimizationProblem.
- MEMORY_FULL_CACHE: ClassVar[str] = 'MemoryFullCache'¶
The name of the
MemoryFullCache.
- property columns_names: list[str | ColumnName]¶
The names of the columns of the dataset.
- data: dict[str, ndarray]¶
The data stored by variable names or group names.
The values are NumPy arrays whose columns are features and rows are observations.
- metadata: dict[str, Any]¶
The metadata used to store any kind of information that are not variables,
E.g. the mesh associated with a multi-dimensional variable.