Note
Go to the end to download the full example code.
Polynomial chaos expansion (PCE)#
A PCERegressor is a PCE model
based on OpenTURNS.
from __future__ import annotations
from matplotlib import pyplot as plt
from numpy import array
from gemseo import create_discipline
from gemseo import create_parameter_space
from gemseo import sample_disciplines
from gemseo.mlearning import create_regression_model
Problem#
In this example,
we represent the function \(f(x)=(6x-2)^2\sin(12x-4)\) [FSK08]
by the AnalyticDiscipline
discipline = create_discipline(
"AnalyticDiscipline",
name="f",
expressions={"y": "(6*x-2)**2*sin(12*x-4)"},
)
and seek to approximate it over the input space
input_space = create_parameter_space()
input_space.add_random_variable("x", "OTUniformDistribution")
To do this, we create a training dataset with 6 equispaced points:
training_dataset = sample_disciplines(
[discipline], input_space, "y", algo_name="PYDOE_FULLFACT", n_samples=10
)
INFO - 16:16:11: *** Start Sampling execution ***
INFO - 16:16:11: Sampling
INFO - 16:16:11: Disciplines: f
INFO - 16:16:11: MDO formulation: MDF
INFO - 16:16:11: Running the algorithm PYDOE_FULLFACT:
INFO - 16:16:11: 10%|█ | 1/10 [00:00<00:00, 675.85 it/sec]
INFO - 16:16:11: 20%|██ | 2/10 [00:00<00:00, 1086.61 it/sec]
INFO - 16:16:11: 30%|███ | 3/10 [00:00<00:00, 1422.28 it/sec]
INFO - 16:16:11: 40%|████ | 4/10 [00:00<00:00, 1697.76 it/sec]
INFO - 16:16:11: 50%|█████ | 5/10 [00:00<00:00, 1915.03 it/sec]
INFO - 16:16:11: 60%|██████ | 6/10 [00:00<00:00, 2107.69 it/sec]
INFO - 16:16:11: 70%|███████ | 7/10 [00:00<00:00, 2272.28 it/sec]
INFO - 16:16:11: 80%|████████ | 8/10 [00:00<00:00, 2423.58 it/sec]
INFO - 16:16:11: 90%|█████████ | 9/10 [00:00<00:00, 2560.10 it/sec]
INFO - 16:16:11: 100%|██████████| 10/10 [00:00<00:00, 2606.29 it/sec]
INFO - 16:16:11: *** End Sampling execution ***
Basics#
Training#
Then, we train an PCE regression model from these samples:
model = create_regression_model("PCERegressor", training_dataset)
model.learn()
WARNING - 16:16:11: Remove input data transformation because PCERegressor does not support transformers.
Prediction#
Once it is built, we can predict the output value of \(f\) at a new input point:
input_value = {"x": array([0.65])}
output_value = model.predict(input_value)
output_value
{'y': array([-0.81106394])}
as well as its Jacobian value:
jacobian_value = model.predict_jacobian(input_value)
jacobian_value
{'y': {'x': array([[18.2279622]])}}
Plotting#
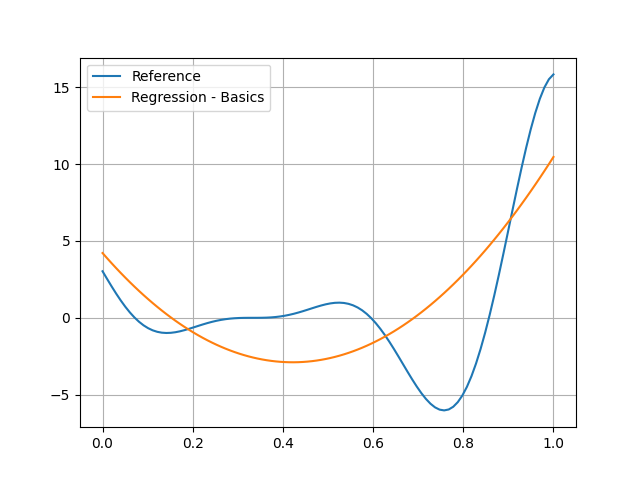
Of course, you can see that the quadratic model is no good at all here:
test_dataset = sample_disciplines(
[discipline], input_space, "y", algo_name="PYDOE_FULLFACT", n_samples=100
)
input_data = test_dataset.get_view(variable_names=model.input_names).to_numpy()
reference_output_data = test_dataset.get_view(variable_names="y").to_numpy().ravel()
predicted_output_data = model.predict(input_data).ravel()
plt.plot(input_data.ravel(), reference_output_data, label="Reference")
plt.plot(input_data.ravel(), predicted_output_data, label="Regression - Basics")
plt.grid()
plt.legend()
plt.show()
INFO - 16:16:11: *** Start Sampling execution ***
INFO - 16:16:11: Sampling
INFO - 16:16:11: Disciplines: f
INFO - 16:16:11: MDO formulation: MDF
INFO - 16:16:11: Running the algorithm PYDOE_FULLFACT:
INFO - 16:16:11: 1%| | 1/100 [00:00<00:00, 4080.06 it/sec]
INFO - 16:16:11: 2%|▏ | 2/100 [00:00<00:00, 3738.24 it/sec]
INFO - 16:16:11: 3%|▎ | 3/100 [00:00<00:00, 3680.29 it/sec]
INFO - 16:16:11: 4%|▍ | 4/100 [00:00<00:00, 3779.50 it/sec]
INFO - 16:16:11: 5%|▌ | 5/100 [00:00<00:00, 3858.61 it/sec]
INFO - 16:16:11: 6%|▌ | 6/100 [00:00<00:00, 3940.78 it/sec]
INFO - 16:16:11: 7%|▋ | 7/100 [00:00<00:00, 3956.89 it/sec]
INFO - 16:16:11: 8%|▊ | 8/100 [00:00<00:00, 4013.21 it/sec]
INFO - 16:16:11: 9%|▉ | 9/100 [00:00<00:00, 4062.50 it/sec]
INFO - 16:16:11: 10%|█ | 10/100 [00:00<00:00, 4108.04 it/sec]
INFO - 16:16:11: 11%|█ | 11/100 [00:00<00:00, 4115.00 it/sec]
INFO - 16:16:11: 12%|█▏ | 12/100 [00:00<00:00, 4136.05 it/sec]
INFO - 16:16:11: 13%|█▎ | 13/100 [00:00<00:00, 4150.25 it/sec]
INFO - 16:16:11: 14%|█▍ | 14/100 [00:00<00:00, 4171.36 it/sec]
INFO - 16:16:11: 15%|█▌ | 15/100 [00:00<00:00, 4199.90 it/sec]
INFO - 16:16:11: 16%|█▌ | 16/100 [00:00<00:00, 4200.34 it/sec]
INFO - 16:16:11: 17%|█▋ | 17/100 [00:00<00:00, 4218.62 it/sec]
INFO - 16:16:11: 18%|█▊ | 18/100 [00:00<00:00, 4243.58 it/sec]
INFO - 16:16:11: 19%|█▉ | 19/100 [00:00<00:00, 4266.38 it/sec]
INFO - 16:16:11: 20%|██ | 20/100 [00:00<00:00, 4271.19 it/sec]
INFO - 16:16:11: 21%|██ | 21/100 [00:00<00:00, 4285.32 it/sec]
INFO - 16:16:11: 22%|██▏ | 22/100 [00:00<00:00, 4296.24 it/sec]
INFO - 16:16:11: 23%|██▎ | 23/100 [00:00<00:00, 4308.00 it/sec]
INFO - 16:16:11: 24%|██▍ | 24/100 [00:00<00:00, 4322.72 it/sec]
INFO - 16:16:11: 25%|██▌ | 25/100 [00:00<00:00, 4321.89 it/sec]
INFO - 16:16:11: 26%|██▌ | 26/100 [00:00<00:00, 4334.51 it/sec]
INFO - 16:16:11: 27%|██▋ | 27/100 [00:00<00:00, 4347.76 it/sec]
INFO - 16:16:11: 28%|██▊ | 28/100 [00:00<00:00, 4360.15 it/sec]
INFO - 16:16:11: 29%|██▉ | 29/100 [00:00<00:00, 4320.49 it/sec]
INFO - 16:16:11: 30%|███ | 30/100 [00:00<00:00, 4325.96 it/sec]
INFO - 16:16:11: 31%|███ | 31/100 [00:00<00:00, 4329.35 it/sec]
INFO - 16:16:11: 32%|███▏ | 32/100 [00:00<00:00, 4339.26 it/sec]
INFO - 16:16:11: 33%|███▎ | 33/100 [00:00<00:00, 4349.30 it/sec]
INFO - 16:16:11: 34%|███▍ | 34/100 [00:00<00:00, 4346.83 it/sec]
INFO - 16:16:11: 35%|███▌ | 35/100 [00:00<00:00, 4353.52 it/sec]
INFO - 16:16:11: 36%|███▌ | 36/100 [00:00<00:00, 4363.39 it/sec]
INFO - 16:16:11: 37%|███▋ | 37/100 [00:00<00:00, 4372.39 it/sec]
INFO - 16:16:11: 38%|███▊ | 38/100 [00:00<00:00, 4373.50 it/sec]
INFO - 16:16:11: 39%|███▉ | 39/100 [00:00<00:00, 4380.42 it/sec]
INFO - 16:16:11: 40%|████ | 40/100 [00:00<00:00, 4389.87 it/sec]
INFO - 16:16:11: 41%|████ | 41/100 [00:00<00:00, 4396.77 it/sec]
INFO - 16:16:11: 42%|████▏ | 42/100 [00:00<00:00, 4402.48 it/sec]
INFO - 16:16:11: 43%|████▎ | 43/100 [00:00<00:00, 4401.70 it/sec]
INFO - 16:16:11: 44%|████▍ | 44/100 [00:00<00:00, 4404.62 it/sec]
INFO - 16:16:11: 45%|████▌ | 45/100 [00:00<00:00, 4410.93 it/sec]
INFO - 16:16:11: 46%|████▌ | 46/100 [00:00<00:00, 4417.38 it/sec]
INFO - 16:16:11: 47%|████▋ | 47/100 [00:00<00:00, 4419.81 it/sec]
INFO - 16:16:11: 48%|████▊ | 48/100 [00:00<00:00, 4412.44 it/sec]
INFO - 16:16:11: 49%|████▉ | 49/100 [00:00<00:00, 4416.57 it/sec]
INFO - 16:16:11: 50%|█████ | 50/100 [00:00<00:00, 4416.82 it/sec]
INFO - 16:16:11: 51%|█████ | 51/100 [00:00<00:00, 4421.54 it/sec]
INFO - 16:16:11: 52%|█████▏ | 52/100 [00:00<00:00, 4379.95 it/sec]
INFO - 16:16:11: 53%|█████▎ | 53/100 [00:00<00:00, 4382.24 it/sec]
INFO - 16:16:11: 54%|█████▍ | 54/100 [00:00<00:00, 4387.94 it/sec]
INFO - 16:16:11: 55%|█████▌ | 55/100 [00:00<00:00, 4392.11 it/sec]
INFO - 16:16:11: 56%|█████▌ | 56/100 [00:00<00:00, 4390.14 it/sec]
INFO - 16:16:11: 57%|█████▋ | 57/100 [00:00<00:00, 4394.85 it/sec]
INFO - 16:16:11: 58%|█████▊ | 58/100 [00:00<00:00, 4400.36 it/sec]
INFO - 16:16:11: 59%|█████▉ | 59/100 [00:00<00:00, 4404.37 it/sec]
INFO - 16:16:11: 60%|██████ | 60/100 [00:00<00:00, 4408.87 it/sec]
INFO - 16:16:11: 61%|██████ | 61/100 [00:00<00:00, 4404.87 it/sec]
INFO - 16:16:11: 62%|██████▏ | 62/100 [00:00<00:00, 4408.10 it/sec]
INFO - 16:16:11: 63%|██████▎ | 63/100 [00:00<00:00, 4412.03 it/sec]
INFO - 16:16:11: 64%|██████▍ | 64/100 [00:00<00:00, 4417.31 it/sec]
INFO - 16:16:11: 65%|██████▌ | 65/100 [00:00<00:00, 4416.92 it/sec]
INFO - 16:16:11: 66%|██████▌ | 66/100 [00:00<00:00, 4419.50 it/sec]
INFO - 16:16:11: 67%|██████▋ | 67/100 [00:00<00:00, 4420.89 it/sec]
INFO - 16:16:11: 68%|██████▊ | 68/100 [00:00<00:00, 4424.85 it/sec]
INFO - 16:16:11: 69%|██████▉ | 69/100 [00:00<00:00, 4427.42 it/sec]
INFO - 16:16:11: 70%|███████ | 70/100 [00:00<00:00, 4423.84 it/sec]
INFO - 16:16:11: 71%|███████ | 71/100 [00:00<00:00, 4427.07 it/sec]
INFO - 16:16:11: 72%|███████▏ | 72/100 [00:00<00:00, 4431.38 it/sec]
INFO - 16:16:11: 73%|███████▎ | 73/100 [00:00<00:00, 4433.92 it/sec]
INFO - 16:16:11: 74%|███████▍ | 74/100 [00:00<00:00, 4431.95 it/sec]
INFO - 16:16:11: 75%|███████▌ | 75/100 [00:00<00:00, 4434.41 it/sec]
INFO - 16:16:11: 76%|███████▌ | 76/100 [00:00<00:00, 4438.73 it/sec]
INFO - 16:16:11: 77%|███████▋ | 77/100 [00:00<00:00, 4442.02 it/sec]
INFO - 16:16:11: 78%|███████▊ | 78/100 [00:00<00:00, 4439.92 it/sec]
INFO - 16:16:11: 79%|███████▉ | 79/100 [00:00<00:00, 4432.18 it/sec]
INFO - 16:16:11: 80%|████████ | 80/100 [00:00<00:00, 4433.90 it/sec]
INFO - 16:16:11: 81%|████████ | 81/100 [00:00<00:00, 4437.43 it/sec]
INFO - 16:16:11: 82%|████████▏ | 82/100 [00:00<00:00, 4441.00 it/sec]
INFO - 16:16:11: 83%|████████▎ | 83/100 [00:00<00:00, 4440.23 it/sec]
INFO - 16:16:11: 84%|████████▍ | 84/100 [00:00<00:00, 4442.89 it/sec]
INFO - 16:16:11: 85%|████████▌ | 85/100 [00:00<00:00, 4445.45 it/sec]
INFO - 16:16:11: 86%|████████▌ | 86/100 [00:00<00:00, 4446.62 it/sec]
INFO - 16:16:11: 87%|████████▋ | 87/100 [00:00<00:00, 4449.51 it/sec]
INFO - 16:16:11: 88%|████████▊ | 88/100 [00:00<00:00, 4448.21 it/sec]
INFO - 16:16:11: 89%|████████▉ | 89/100 [00:00<00:00, 4451.07 it/sec]
INFO - 16:16:11: 90%|█████████ | 90/100 [00:00<00:00, 4455.23 it/sec]
INFO - 16:16:11: 91%|█████████ | 91/100 [00:00<00:00, 4459.47 it/sec]
INFO - 16:16:11: 92%|█████████▏| 92/100 [00:00<00:00, 4463.26 it/sec]
INFO - 16:16:11: 93%|█████████▎| 93/100 [00:00<00:00, 4461.72 it/sec]
INFO - 16:16:11: 94%|█████████▍| 94/100 [00:00<00:00, 4465.21 it/sec]
INFO - 16:16:11: 95%|█████████▌| 95/100 [00:00<00:00, 4468.68 it/sec]
INFO - 16:16:11: 96%|█████████▌| 96/100 [00:00<00:00, 4471.54 it/sec]
INFO - 16:16:11: 97%|█████████▋| 97/100 [00:00<00:00, 4470.51 it/sec]
INFO - 16:16:11: 98%|█████████▊| 98/100 [00:00<00:00, 4472.27 it/sec]
INFO - 16:16:11: 99%|█████████▉| 99/100 [00:00<00:00, 4474.77 it/sec]
INFO - 16:16:11: 100%|██████████| 100/100 [00:00<00:00, 4424.28 it/sec]
INFO - 16:16:11: *** End Sampling execution ***
Settings#
The PCERegressor has many options
defined in the PCERegressor_Settings Pydantic model.
Degree#
model = create_regression_model("PCERegressor", training_dataset, degree=3)
model.learn()
WARNING - 16:16:11: Remove input data transformation because PCERegressor does not support transformers.
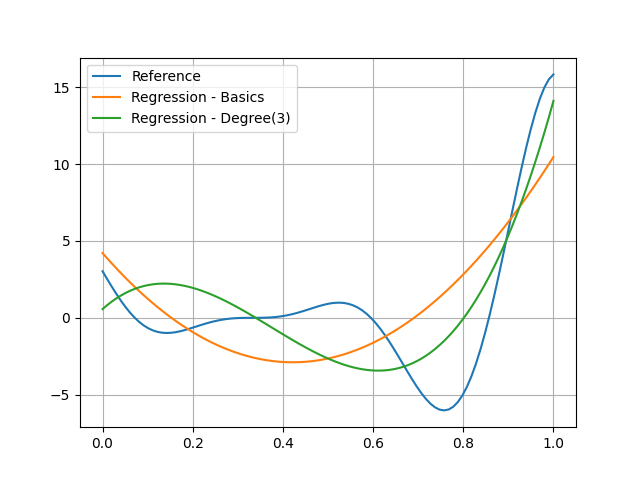
and see that this model seems to be better:
predicted_output_data_ = model.predict(input_data).ravel()
plt.plot(input_data.ravel(), reference_output_data, label="Reference")
plt.plot(input_data.ravel(), predicted_output_data, label="Regression - Basics")
plt.plot(input_data.ravel(), predicted_output_data_, label="Regression - Degree(3)")
plt.grid()
plt.legend()
plt.show()
Total running time of the script: (0 minutes 0.185 seconds)