Machine learning#
This section illustrates the features of the gemseo.mlearning package:
how to create a machine learning model for classification, clustering or regression,
how to transform the data,
how to assess the quality of a model,
how to tune a model.
This package is particularly useful for creating a surrogate model,
as a SurrogateDiscipline wraps a regression model built from it.
However,
for those who are not very comfortable with machine learning
and for those who are essentially interested in the surrogate modelling,
starting with the examples
about the SurrogateDiscipline should be more relevant.
Calibration and selection#
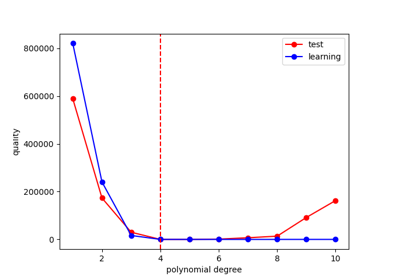
During the training stage, the parameters of a machine learning model are modified so that this model learns the training data as well as possible.
This model also depends on hyperparameters that are fixed during training.
For example, the polynomial degree in the case of polynomial regression.
The MLAlgoCalibration class can be used
to tune these hyperparameters so as to improve this model.
Moreover,
even if this model has learned well,
it is possible that another has learned better.
The MLAlgoSelection class can be used
to select the best machine learning model from a collection.
Classification#
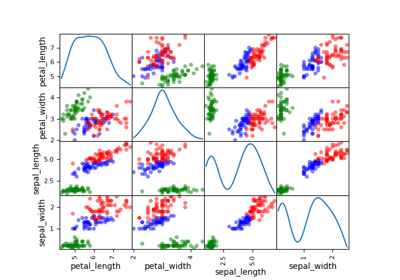
The purpose of a classification model is to predict the label value corresponding to a feature value after being trained from several feature-label samples.



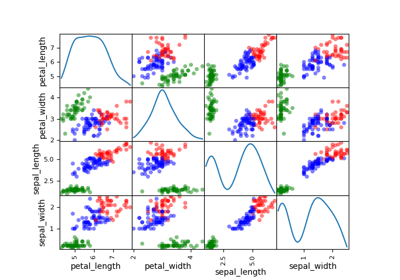
Clustering#
The purpose of a clustering model is to group training observations according to their similarities.

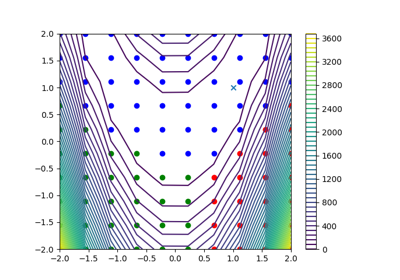
Dimension reduction#
How to reduce the dimension of a high-dimensional variable.
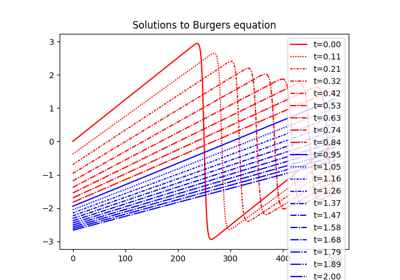
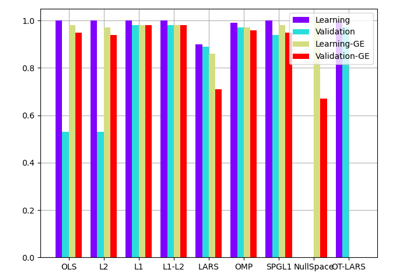
Quality#
It is important to evaluate the quality of a machine learning model before using it. GEMSEO proposes numerical measures and visualizations for this purpose.
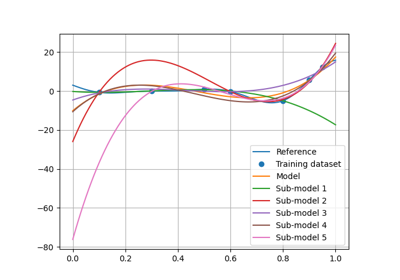

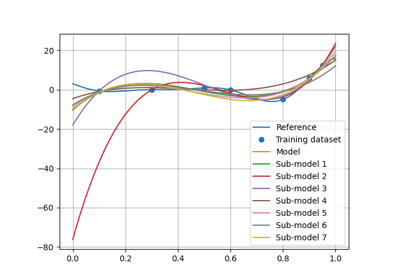
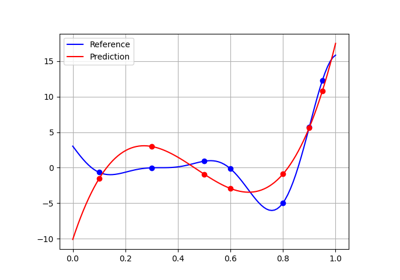
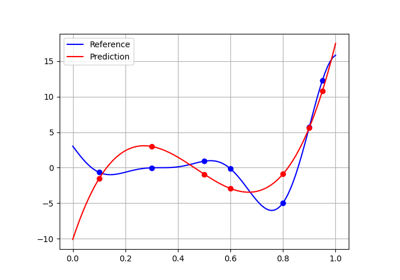
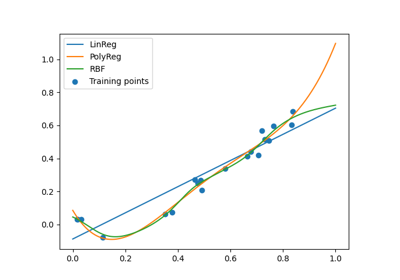
Regression#
The purpose of a regression model is to predict the output value corresponding to an input value after being trained from several input-output samples.

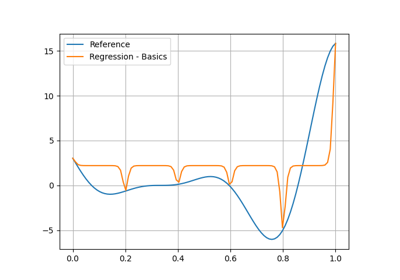




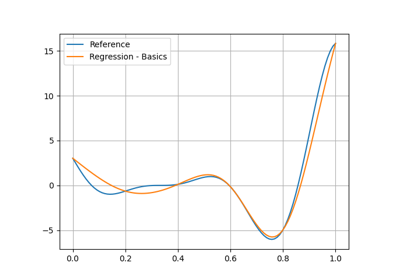
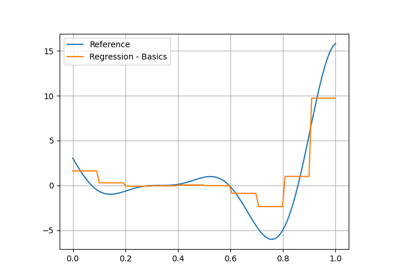
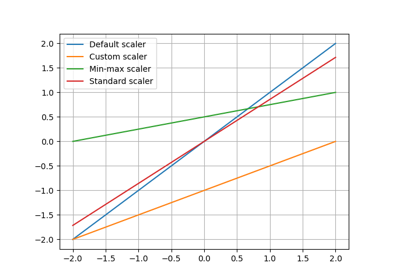
Data transformation#
Fitting a model from transformed data rather than raw data can facilitate the training
and improve the quality of the machine learning model.
Every machine learning model has a transformer argument to set the transformation policy (none by default).
In the special case of regression models,
the function create_surrogate() and the SurrogateDiscipline class
use the BaseRegressor.DEFAULT_TRANSFORMER by default,
which is MinMaxScaler for both inputs and outputs.