supervised module¶
This module contains the base class for the supervised machine learning algorithms.
Supervised machine learning is a task of learning relationships between input and output variables based on an input-output dataset. One usually distinguishes between two types of supervised machine learning algorithms, based on the nature of the outputs. For a continuous output variable, a regression is performed, while for a discrete output variable, a classification is performed.
Given a set of input variables \(x \\in \\mathbb{R}^{n_{\\text{samples}}\\times n_{\\text{inputs}}}\) and a set of output variables \(y\\in \\mathbb{K}^{n_{\\text{samples}}\\times n_{\\text{outputs}}}\), where \(n_{\\text{inputs}}\) is the dimension of the input variable, \(n_{\\text{outputs}}\) is the dimension of the output variable, \(n_{\\text{samples}}\) is the number of training samples and \(\\mathbb{K}\) is either \(\\mathbb{R}\) or \(\\mathbb{N}\) for regression and classification tasks respectively, a supervised learning algorithm seeks to find a function \(f: \\mathbb{R}^{n_{\\text{inputs}}} \\to \\mathbb{K}^{n_{\\text{outputs}}}\) such that \(y=f(x)\).
In addition, we often want to impose some additional constraints on the function \(f\), mainly to ensure that it has a generalization capacity beyond the training data, i.e. it is able to correctly predict output values of new input values. This is called regularization. Assuming \(f\) is parametrized by a set of parameters \(\\theta\), and denoting \(f_\\theta\) the parametrized function, one typically seeks to minimize a function of the form
where \(\\mu\) is a distance-like measure, typically a mean squared error, a cross entropy in the case of a regression, or a probability to be maximized in the case of a classification, and \(\\Omega\) is a regularization term that limits the parameters from over-fitting, typically some norm of its argument.
The supervised module implements this concept
through the MLSupervisedAlgo class based on an IODataset.
- class gemseo.mlearning.core.supervised.MLSupervisedAlgo(data, transformer=mappingproxy({}), input_names=None, output_names=None, **parameters)[source]
Bases:
MLAlgoSupervised machine learning algorithm.
Inheriting classes shall overload the
MLSupervisedAlgo._fit()andMLSupervisedAlgo._predict()methods.- Parameters:
data (IODataset) – The learning dataset.
transformer (TransformerType) –
The strategies to transform the variables. The values are instances of
Transformerwhile the keys are the names of either the variables or the groups of variables, e.g."inputs"or"outputs"in the case of the regression algorithms. If a group is specified, theTransformerwill be applied to all the variables of this group. IfIDENTITY, do not transform the variables.By default it is set to {}.
input_names (Iterable[str] | None) – The names of the input variables. If
None, consider all the input variables of the learning dataset.output_names (Iterable[str] | None) – The names of the output variables. If
None, consider all the output variables of the learning dataset.**parameters (MLAlgoParameterType) – The parameters of the machine learning algorithm.
- Raises:
ValueError – When both the variable and the group it belongs to have a transformer.
- DataFormatters
alias of
SupervisedDataFormatters
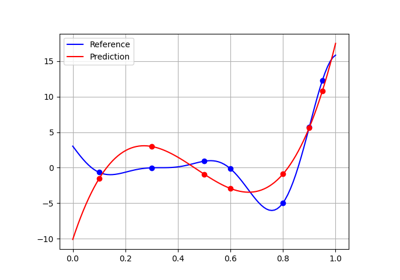
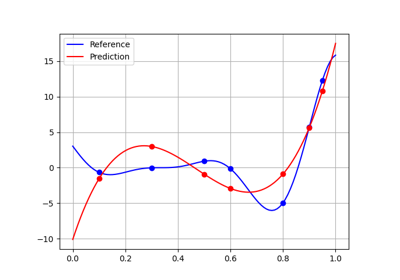
- predict(input_data)[source]
Predict output data from input data.
The user can specify these input data either as a NumPy array, e.g.
array([1., 2., 3.])or as a dictionary, e.g.{'a': array([1.]), 'b': array([2., 3.])}.If the numpy arrays are of dimension 2, their i-th rows represent the input data of the i-th sample; while if the numpy arrays are of dimension 1, there is a single sample.
The type of the output data and the dimension of the output arrays will be consistent with the type of the input data and the size of the input arrays.
- DEFAULT_TRANSFORMER: DefaultTransformerType = mappingproxy({'inputs': <gemseo.mlearning.transformers.scaler.min_max_scaler.MinMaxScaler object>})
The default transformer for the input and output data, if any.
- SHORT_ALGO_NAME: ClassVar[str] = 'MLSupervisedAlgo'
The short name of the machine learning algorithm, often an acronym.
Typically used for composite names, e.g.
f"{algo.SHORT_ALGO_NAME}_{dataset.name}"orf"{algo.SHORT_ALGO_NAME}_{discipline.name}".
- algo: Any
The interfaced machine learning algorithm.
- property input_data: ndarray
The input data matrix.
- property input_dimension: int
The input space dimension.
- learning_set: Dataset
The learning dataset.
- property output_data: ndarray
The output data matrix.
- property output_dimension: int
The output space dimension.
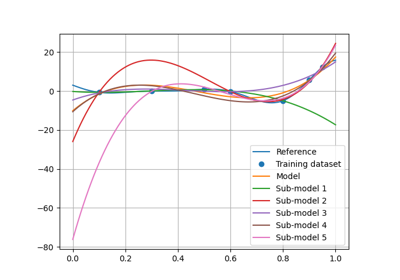
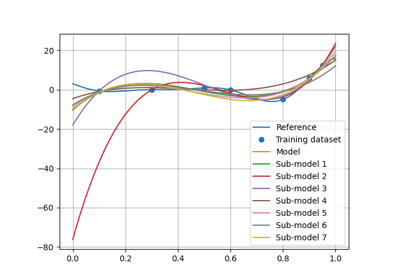
- resampling_results: dict[str, tuple[Resampler, list[MLAlgo], list[ndarray] | ndarray]]
The resampler class names bound to the resampling results.
A resampling result is formatted as
(resampler, ml_algos, predictions)whereresampleris aResampler,ml_algosis the list of the associated machine learning algorithms built during the resampling stage andpredictionsare the predictions obtained with the latter.resampling_resultsstores only one resampling result per resampler type (e.g.,"CrossValidation","LeaveOneOut"and"Boostrap").
- transformer: dict[str, Transformer]
The strategies to transform the variables, if any.
The values are instances of
Transformerwhile the keys are the names of either the variables or the groups of variables, e.g. “inputs” or “outputs” in the case of the regression algorithms. If a group is specified, theTransformerwill be applied to all the variables of this group.