Scalable models#
A scalable methodology to test MDO formulation on benchmark or real problems.
This API facilitates
the use of the gemseo.problems.mdo.scalable.data_driven.study
package implementing classes to benchmark MDO formulations
based on scalable disciplines.
ScalabilityStudy class implements the concept of scalability study:
By instantiating a
ScalabilityStudy, the user defines the MDO problem in terms of design parameters, objective function and constraints.For each discipline, the user adds a dataset stored in a
Datasetand select a type ofScalableModelto build theScalableDisciplineassociated with this discipline.The user adds different optimization strategies, defined in terms of both optimization algorithms and MDO formulation.
The user adds different scaling strategies, in terms of sizes of design parameters, coupling variables and equality and inequality constraints. The user can also define a scaling strategies according to particular parameters rather than groups of parameters.
Lastly, the user executes the
ScalabilityStudyand the results are written in several files and stored into directories in a hierarchical way, where names depend on both MDO formulation, scaling strategy and replications when it is necessary. Different kinds of files are stored: optimization graphs, dependency matrix plots and of course, scalability results by means of a dedicated class:ScalabilityResult.
- create_scalability_study(objective, design_variables, directory='study', prefix='', eq_constraints=None, ineq_constraints=None, maximize_objective=False, fill_factor=0.7, active_probability=0.1, feasibility_level=0.8, start_at_equilibrium=True, early_stopping=True, coupling_variables=None)[source]
This method creates a
ScalabilityStudy.It requires two mandatory arguments:
the
'objective'name,the list of
'design_variables'names.
Concerning output files, we can specify:
the
directorywhich is'study'by default,the prefix of output file names (default: no prefix).
Regarding optimization parametrization, we can specify:
the list of equality constraints names (
eq_constraints),the list of inequality constraints names (
ineq_constraints),the choice of maximizing the objective function (
maximize_objective).
By default, the objective function is minimized and the MDO problem is unconstrained.
Last but not least, with regard to the scalability methodology, we can overwrite:
the default fill factor of the input-output dependency matrix
ineq_constraints,the probability to set the inequality constraints as active at initial step of the optimization
active_probability,the offset of satisfaction for inequality constraints
feasibility_level,the use of a preliminary MDA to start at equilibrium
start_at_equilibrium,the post-processing of the optimization database to get results earlier than final step
early_stopping.
- Parameters:
objective (str) -- The name of the objective.
design_variables (Iterable[str]) -- The names of the design variables.
directory (str) --
The working directory of the study.
By default it is set to "study".
prefix (str) --
The prefix for the output filenames.
By default it is set to "".
eq_constraints (Iterable[str] | None) -- The names of the equality constraints, if any.
ineq_constraints (Iterable[str] | None) -- The names of the inequality constraints, if any.
maximize_objective (bool) --
Whether to maximize the objective.
By default it is set to False.
fill_factor (float) --
The default fill factor of the input-output dependency matrix.
By default it is set to 0.7.
active_probability (float) --
The probability to set the inequality constraints as active at initial step of the optimization.
By default it is set to 0.1.
feasibility_level (float) --
The offset of satisfaction for the inequality constraints.
By default it is set to 0.8.
start_at_equilibrium (bool) --
Whether to start at equilibrium using a preliminary MDA.
By default it is set to True.
early_stopping (bool) --
Whether to post-process the optimization database to get results earlier than final step.
By default it is set to True.
coupling_variables (Iterable[str] | None) -- The names of the coupling variables.
- Return type:
- plot_scalability_results(study_directory)[source]
Plot
ScalabilityResult`s generated by a :class:.ScalabilityStudy`.- Parameters:
study_directory (str) -- The directory of the scalability study.
- Return type:
Scalable MDO problem.
This module implements the concept of scalable problem by means of the
ScalableProblem class.
Given
an MDO scenario based on a set of sampled disciplines with a particular problem dimension,
a new problem dimension (= number of inputs and outputs),
a scalable problem:
makes each discipline scalable based on the new problem dimension,
creates the corresponding MDO scenario.
Then, this MDO scenario can be executed and post-processed.
We can repeat this tasks for different sizes of variables and compare the scalability, which is the dependence of the scenario results on the problem dimension.
See also
Discipline, ScalableDiscipline
and Scenario
- class ScalableProblem(datasets, design_variables, objective_function, eq_constraints=None, ineq_constraints=None, maximize_objective=False, sizes=None, **parameters)[source]
Scalable problem.
- Parameters:
datasets (Iterable[IODataset]) -- One input-output dataset per discipline.
design_variables (Iterable[str]) -- The names of the design variables.
objective_function (str) -- The name of the objective.
eq_constraints (Iterable[str] | None) -- The names of the equality constraints, if any.
ineq_constraints (Iterable[str] | None) -- The names of the inequality constraints, if any.
maximize_objective (bool) --
Whether to maximize the objective.
By default it is set to False.
sizes (Mapping[str, int] | None) -- The sizes of the inputs and outputs. If
None, use the original sizes.**parameters (Any) -- The optional parameters of the scalable model.
- create_scenario(formulation_name='DisciplinaryOpt', scenario_type='MDO', start_at_equilibrium=False, active_probability=0.1, feasibility_level=0.5, **formulation_settings)[source]
Create a
Scenariofrom the scalable disciplines.- Parameters:
formulation_name (str) --
The MDO formulation to use for the scenario.
By default it is set to "DisciplinaryOpt".
scenario_type (str) --
The type of scenario, either
MDOorDOE.By default it is set to "MDO".
start_at_equilibrium (bool) --
Whether to start at equilibrium using a preliminary MDA.
By default it is set to False.
active_probability (float) --
The probability to set the inequality constraints as active at the initial step of the optimization.
By default it is set to 0.1.
feasibility_level (float) --
The offset of satisfaction for inequality constraints.
By default it is set to 0.5.
**formulation_settings (Any) -- The formulation settings.
- Returns:
The
Scenariofrom the scalable disciplines.- Return type:
- get_execution_duration(do_sum=True)[source]
Get the total execution time.
- plot_1d_interpolations(save=True, show=False, step=0.01, varnames=None, directory='.', png=False)[source]
Plot 1d interpolations.
- Parameters:
save (bool) --
Whether to save the figure.
By default it is set to True.
show (bool) --
Whether to display the figure.
By default it is set to False.
step (float) --
The step to evaluate the 1d interpolation function.
By default it is set to 0.01.
varnames (Sequence[str] | None) -- The names of the variable to plot. If
None, all the variables are plotted.directory (Path | str) --
The directory path.
By default it is set to ".".
png (bool) --
Whether to use PNG file format instead of PDF.
By default it is set to False.
- plot_coupling_graph()[source]
Plot a coupling graph.
- Return type:
None
- plot_dependencies(save=True, show=False, directory='.')[source]
Plot dependency matrices.
- plot_n2_chart(save=True, show=False)[source]
Plot a N2 chart.
- property is_feasible: bool
Whether the solution is feasible.
- property n_calls_linearize: dict[str, int]
The number of disciplinary linearizations per discipline.
- property n_calls_linearize_top_level: dict[str, int]
The number of top-level disciplinary linearizations per discipline.
- property n_calls_top_level: dict[str, int]
The number of top-level disciplinary calls per discipline.
- property status: int
The status of the scenario.
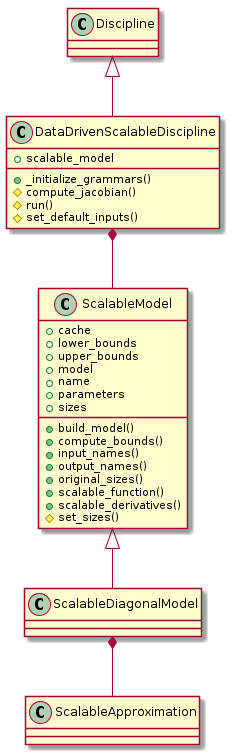
Scalable discipline.
The discipline
implements the concept of scalable discipline.
This is a particular discipline
built from an input-output training dataset associated with a function
and generalizing its behavior to a new user-defined problem dimension,
that is to say new user-defined input and output dimensions.
Alone or in interaction with other objects of the same type, a scalable discipline can be used to compare the efficiency of an algorithm applying to disciplines with respect to the problem dimension, e.g. optimization algorithm, surrogate model, MDO formulation, MDA, ...
The ScalableDiscipline class implements this concept.
It inherits from the Discipline class
in such a way that it can easily be used in a Scenario.
It is composed of a ScalableModel.
The user only needs to provide:
the name of a class overloading
ScalableModel,a dataset as an
Datasetvariables sizes as a dictionary whose keys are the names of inputs and outputs and values are their new sizes. If a variable is missing, its original size is considered.
The ScalableModel parameters can also be filled in,
otherwise the model uses default values.
- class DataDrivenScalableDiscipline(name, data, sizes=mappingproxy({}), **parameters)[source]
A scalable discipline.
Initialize self. See help(type(self)) for accurate signature.
- Parameters:
- execution_statistics: ExecutionStatistics
The execution statistics of the process.
- execution_status: ExecutionStatus
The execution status of the process.
- jac: JacobianData
The Jacobian matrices of the outputs.
The structure is
{output_name: {input_name: jacobian_matrix}}.
- name: str
The name of the process.
A factory of scalable models.
- class ScalableModelFactory[source]
A factory of scalable models.
- Return type:
Any
Scalable model.
This module implements the abstract concept of scalable model which is used by scalable disciplines. A scalable model is built from an input-output training dataset associated with a function and generalizing its behavior to a new user-defined problem dimension, that is to say new user-defined input and output dimensions.
The concept of scalable model is implemented
through ScalableModel, an abstract class which is instantiated from:
data provided as a
Datasetvariables sizes provided as a dictionary whose keys are the names of inputs and outputs and values are their new sizes. If a variable is missing, its original size is considered.
Scalable model parameters can also be filled in. Otherwise, the model uses default values.
See also
The ScalableDiagonalModel class overloads ScalableModel.
- class ScalableModel(data, sizes=mappingproxy({}), **parameters)[source]
A scalable model.
- Parameters:
- build_model()[source]
Build model with original sizes for input and output variables.
- Return type:
None
- compute_bounds()[source]
Compute lower and upper bounds of both input and output variables.
- normalize_data()[source]
Normalize the dataset from lower and upper bounds.
- Return type:
None
- scalable_derivatives(input_value=None)[source]
Evaluate the scalable derivatives.
- Parameters:
input_value -- The input values. If
None, use the default inputs.- Returns:
The evaluations of the scalable derivatives.
- Return type:
None
- scalable_function(input_value=None)[source]
Evaluate the scalable function.
- Parameters:
input_value -- The input values. If
None, use the default inputs.- Returns:
The evaluations of the scalable function.
- Return type:
None
- data: IODataset
The training dataset.
Scalable diagonal model.
This module implements the concept of scalable diagonal model, which is a particular scalable model built from an input-output dataset relying on a diagonal design of experiments (DOE) where inputs vary proportionally from their lower bounds to their upper bounds, following the diagonal of the input space.
So for every output, the dataset catches its evolution with respect to this proportion, which makes it a mono dimensional behavior. Then, for a new user-defined problem dimension, the scalable model extrapolates this mono dimensional behavior to the different input directions.
The concept of scalable diagonal model is implemented through
the ScalableDiagonalModel class
which is composed of a ScalableDiagonalApproximation.
With regard to the diagonal DOE, GEMSEO proposes the
DiagonalDOE class.
- class ScalableDiagonalApproximation(sizes, output_dependency, io_dependency)[source]
Methodology that captures the trends of a physical problem.
It also extends it into a problem that has scalable input and outputs dimensions. The original and the resulting scalable problem have the same interface:
all inputs and outputs have the same names; only their dimensions vary.
- Parameters:
- static scale_samples(samples)[source]
Scale array samples into [0, 1].
- build_scalable_function(function_name, dataset, input_names, degree=3)[source]
Create the interpolation functions for a specific output.
- Parameters:
- Returns:
The input and output samples scaled in [0, 1].
- Return type:
- get_scalable_derivative(output_function)[source]
Return the function computing the derivatives of an output.
- class ScalableDiagonalModel(data, sizes=mappingproxy({}), fill_factor=-1, comp_dep=None, inpt_dep=None, force_input_dependency=False, allow_unused_inputs=True, seed=0, group_dep=mappingproxy({}))[source]
Scalable diagonal model.
- Parameters:
data (IODataset) -- The training dataset.
The sizes of the input and output variables. If empty, use the original sizes.
By default it is set to {}.
fill_factor (float) --
The degree of sparsity of the dependency matrix.
By default it is set to -1.
comp_dep (NDArray[float] | None) -- The matrix defining the selection of a single original component for each scalable component. If
None, generate a random matrix.inpt_dep (NDArray[float] | None) -- The input-output dependency matrix. If
None, generate a random matrix.force_input_dependency (bool) --
Whether to force the dependency of each output with at least one input.
By default it is set to False.
allow_unused_inputs (bool) --
The possibility to have an input with no dependence with any output.
By default it is set to True.
seed (int) --
The seed for reproducible results.
By default it is set to 0.
group_dep (Mapping[str, Iterable[str]]) --
The dependency between the inputs and outputs.
By default it is set to {}.
- build_model()[source]
Build the model with the original sizes for input and output variables.
- Returns:
The scalable approximation.
- Return type:
- generate_random_dependency()[source]
Generate a random dependency structure for use in scalable discipline.
- plot_1d_interpolations(save=False, show=False, step=0.01, varnames=(), directory='.', png=False)[source]
Plot the scaled 1D interpolations, a.k.a. the basis functions.
A basis function is a mono dimensional function interpolating the samples of a given output component over the input sampling line \(t\in[0,1]\mapsto \underline{x}+t(\overline{x}-\underline{x})\).
There are as many basis functions as there are output components from the discipline. Thus, for a discipline with a single output in dimension 1, there is 1 basis function. For a discipline with a single output in dimension 2, there are 2 basis functions. For a discipline with an output in dimension 2 and an output in dimension 13, there are 15 basis functions. And so on. This method allows to plot the basis functions associated with all outputs or only part of them, either on screen (
show=True), in a file (save=True) or both. We can also specify the discretizationstepwhose default value is0.01.- Parameters:
save (bool) --
Whether to save the figure.
By default it is set to False.
show (bool) --
Whether to display the figure.
By default it is set to False.
step (float) --
The step to evaluate the 1d interpolation function.
By default it is set to 0.01.
varnames (Sequence[str]) --
The names of the variable to plot. If empty, all the variables are plotted.
By default it is set to ().
directory (str) --
The directory path.
By default it is set to ".".
png (bool) --
Whether to use PNG file format instead of PDF.
By default it is set to False.
- Returns:
The names of the files.
- Return type:
- plot_dependency(add_levels=True, save=True, show=False, directory='.', png=False)[source]
Plot the dependency matrix of a discipline in the form of a chessboard.
The rows represent inputs, columns represent output and gray scale represents the dependency level between inputs and outputs.
- Parameters:
add_levels (bool) --
Whether to add the dependency levels in percentage.
By default it is set to True.
save (bool) --
Whether to save the figure.
By default it is set to True.
show (bool) --
Whether to display the figure.
By default it is set to False.
directory (str) --
The directory path.
By default it is set to ".".
png (bool) --
Whether to use PNG file format instead of PDF.
By default it is set to False.
- Return type:
- scalable_derivatives(input_value=None)[source]
Compute the derivatives.
- scalable_function(input_value=None)[source]
Compute the outputs.
- data: IODataset
The training dataset.